Anatomy of a Word Search Game
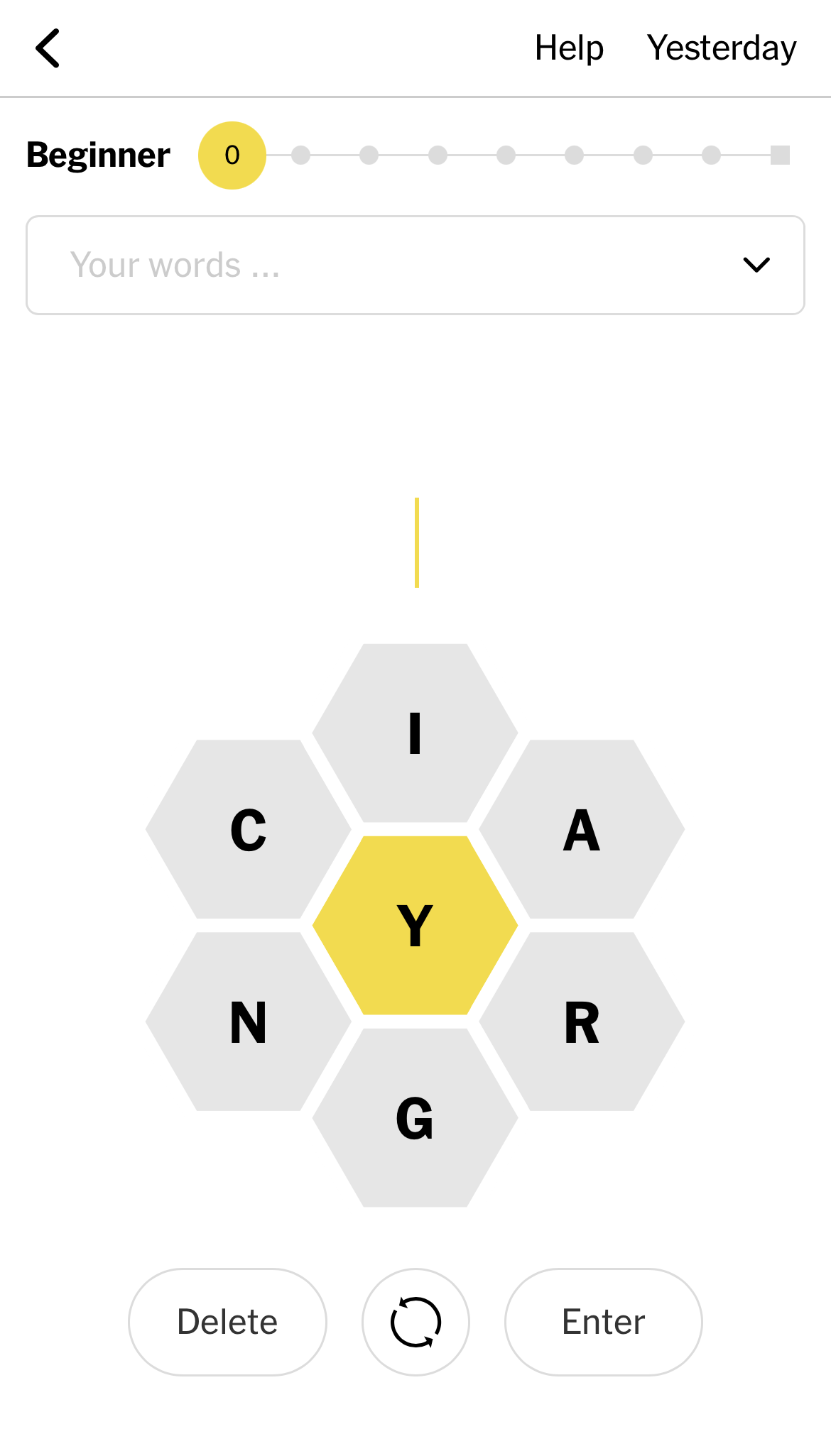
The New York Times has a daily game called Spelling Bee. Here are the basics of the game:
- The board features 7 letters in a honeycomb array with one highlighted letter in the middle.
- Goal is to find as many valid words as possible. A valid word is any word that is at least 4 letters in length and includes the center letter. Letters can be used more than once.
- All puzzles include at least one pangram — a word that uses all 7 letters on the board at least once.
- Scoring works as follows: 4 letter words are worth 1 point each. All other words are worth 1 point for each letter in the word. Pangrams are worth an additional 7 points each.
Building the database
To replicate the game I first need a dictionary of words to choose from. The dictionary can be whatever I want. This scrabble dictionary was a good enough starting point and had the added benefit of not having any duplicates in the list.
I have a MySQL server on my home machine. It’s easy enough to import a txt or csv file into my database, but before I did that I wanted to make some useful modifications to the word list for faster querying later.
Random letters?
Each day the NYT features a new septet of letters. In building my replica of this game I could just pick an arbitrary set of 7 letters and put one of them in the middle and then check each word submission after the fact. This has a couple of glaring problems:
- No guarantee of any valid words, and
- No guarantee of a pangram
Point 2 seemed to be the key for the whole game setup. Having at least one pangram is a sufficient condition for a valid game board. So I knew I was going to need to be able to determine which words in my list were valid pangrams. How could I do this?
In short a given word is a pangram if the number of unique letters in that word is exactly 7. So I decided to write a utility function to help:
const uniqueChars = str => [...(new Set([...str]))].join("");
[…str] turns my string into an array of individual characters. Set turns this array into a set which has the added benefit of removing any duplicate characters. Wrapping this with […<set>] turns our set back into an array which finally allows us to chain .join("") to yield a string of all the unique characters. With this I could then write another utility function:
const isPangram = str => uniqueChars(str).length === 7;
I could extend the initial txt file to replace each line so <word> becomes
<word>,<is_pangram> which would shape my MySQL table accordingly.
Now I’d be able to tell if a given word was a candidate for for my pangram. So instead of
SELECT random_word FROM dictionary;
until I get something that works I’d be able to query
SELECT random_word FROM dictionary
WHERE is_pangram IS TRUE;
Getting all valid words
With the approach thus far I would be able to query for a single pangram. With this one word I could then choose one of the characters to be the center character and let the user try and find the rest of the words. After all, determining whether or not a set of letters is a word in the dictionary is a straightforward query:
SELECT * FROM dictionary
WHERE word = <submitted_guess>;
But this has a couple of drawbacks:
- Every guess requires another roundtrip call to my MySQL server
- No obvious way to know if I’ve guessed all possible words from the set of 7 letters given to the user
What if I could get all valid words in a single query? What would I need to know up front?
- Which words were made up of a subset of my initial 7 letters
- Which of those included the required central letter
The challenge from a query perspective is that I don’t want to try and determine character sets on the fly. MySQL isn’t set up to do this efficiently (if at all) adding a lot of compute time to such a query.
One way to go about this is calculating the unique characters and adding to the dictionary table as a standalone column. Then I will be able to filter all words whose unique characters match a specified character subset of the original 7. Recall our earlier function
const uniqueChars = str => [...(new Set([...str]))].join("");
This is a good start, but falls a little short if I want to use as a key in my table. For example consider the words read and dared:
uniqueChars("read"); // "read"
uniqueChars("dared"); // "dare"
The letter sets for each of these words is the same but MySQL doesn’t know this. I need a way to consistently represent the same letter sets even if they’re string order isn’t the same. One way to solve this is to sort the letter array alphabetically before rejoining. I can modify the function to be
const uniqueChars = str =>
[...(new Set([...str]))].sort().join("");
Then I have
uniqueChars("read"); // "ader"
uniqueChars("dared"); // "ader"
If I add this string as a separate column I can quickly and easily query all words that can be formed from the same set of letters. For the above example such a query would be
SELECT word FROM dictionary
WHERE char_set = "ader";
But this only retrieves the words for one character set. I need all possible character subsets from the pangram. If only looking at the above character set. If read were my word, ader is the character set and here are all the (non-empty) character subsets:
a
d
e
r
ad
ae
ar
de
dr
er
ade
adr
aer
der
ader
If I wanted all words with any of these character sets my query would look like
SELECT word FROM dictionary
WHERE char_set = "a"
OR char_set = "d"
OR char_set = "e"
OR char_set = "r"
OR char_set = "ad"
OR char_set = "ae"
OR char_set = "ar"
OR char_set = "de"
OR char_set = "dr"
OR char_set = "er"
OR char_set = "ade"
OR char_set = "adr"
OR char_set = "aer"
OR char_set = "der"
OR char_set = "ader";
Even though the query is verbose, its runtime performance scales linearly so it looks worse than it actually is.
What’s left to do then is to write a way to generate all relevant character sets from a pangram and specified center letter.
Find all subsets
WARNING A little combinatorics aside incoming.
Let’s count the number of total subsets that can be made from a set of N unique elements. One way to count them is to realize that for a given element in the superset each subset either contains or does not contain that particular element. That is there are 2 choices (include or exclude) for each of the N elements. These choices compound as their inclusion or exclusion is independent from the inclusion or exclusion of another element in the superset. So there are then
2 × 2 × ... × 2 = 2^N
possible subsets. For my purposes I can ignore the subset where all elements are excluded (the empty set).
Subsets to strings
Now that the number of subsets is understood, how can I get the string equivalent for each. In keeping with the base 2 nature of the combinatorial argument above I can look to binary numbers. If I count from 1 to 2^N in binary for the ["a", "d", "e", "r"] example (N = 4):
0001
0010
0011
0100
...
1110
1111
If I take any of these binary representations, overlay them on the superset and say all 0s are excluded and only 1s are included I get
0001 0010 0011 0100 1110 1111
ader ader ader ader ader ader
---- ---- ---- ---- ... ---- ----
r e er d ade ader
Even though the order of the subsets isn’t alphabetical it is complete. Algorithmically this looks like
const getAllSubsets = (str) => {
const subsets = [];
for (i = 1; i < Math.pow(2, str.length); i++) {
// e.g. 5 -> "101"
const binary = i.toString(2);
// "0" + "101" -> "0101"
const binaryWithLeadingZeroes = "0".repeat(str.length - binary.length) + binary;
// "0101" -> ["0", "1", "0", "1"]
const binaryArr = binaryWithLeadingZeroes.split("");
const subset = [];
binaryArr.forEach((bit, position) => {
if (bit === "1") {
subset.push(str[position]);
}
});
subsets.push(subset.join(""));
}
return subsets;
};
Keep in mind this will give all non-empty subsets. This is about twice the number of wanted subsets after the random center character is determined. I can modify the above function to further filter based on a passed extra parameter
const getAllSubsets = (str, centerChar) => {
const centerIndex = str.indexOf(centerChar);
const subsets = [];
for (i = 1; i < Math.pow(2, str.length); i++) {
// e.g. 5 -> "101"
const binary = i.toString(2);
// "0" + "101" -> "0101"
const binaryWithLeadingZeroes = "0".repeat(str.length - binary.length) + binary;
// "0101" -> ["0", "1", "0", "1"]
const binaryArr = binaryWithLeadingZeroes.split("");
const subset = [];
// no need to iterate through if required
// character won't be in resulting subset
if (binaryArr[centerIndex] === "0") {
continue;
}
binaryArr.forEach((bit, position) => {
if (bit === "1") {
subset.push(str[position]);
}
});
subsets.push(subset.join(""));
}
return subsets;
};
Applying the modified version to a contrived example for "ader" with a required center letter of say "d"
getAllSubsets("ader", "d");
/***
[
"d",
"dr",
"de",
"der",
"ad",
"adr",
"ade",
"ader"
]
***/
Creating SQL query
Using the above I can create the query that will retrieve all matching words
const createQuery = (charSetStr, centerChar) => {
const subsets = getAllSubsets(charSetStr, centerChar);
return `
SELECT word FROM dictionary
WHERE ${subsets.map(str => `char_set = "${str}"`).join(" OR ")};`;
};
Appendix
Extending word list CSV
With a little bit of node fs and an npm package called I can combine our utility functions to extend our dictionary txt file into a csv that gets fed to MySQL
import fs from "fs";
import readline from "linebyline";
const rl = readline("dict.txt");
const uniqueChars = str =>
[...(new Set([...str]))].sort().join("");
const isPangram = str => uniqueChars(str).length === 7;
rl.on("line", (ln) => {
const modifiedLine = `${ln},${uniqueChars(ln)},${isPangram(ln) ? 1 : 0}\n`;
fs.appendFileSync("ext_dict.csv", modifiedLine);
});
Getting a random pangram
It’s a bit outside the scope of this conversation but this is how I can query a random pangram once is_pangram and char_set columns have been added to the dictionary table
SELECT char_set
FROM dictionary AS r1
JOIN (
SELECT CEIL(RAND() * (
SELECT MAX(id)
FROM dictionary
WHERE is_pangram IS TRUE
)) AS id
) AS r2
WHERE r1.id >= r2.id
AND r1.is_pangram IS TRUE
ORDER BY r1.id ASC
LIMIT 1;